本文共 4156 字,大约阅读时间需要 13 分钟。
原文链接:
之前就对Python爬虫和机器学习很感兴趣,最近终于是开始学习了....
好吧,不是没时间,而是有时间的时候都干别的了,所以对于还需要抽时间学我只能是‘好吧’的态度...
今天急急忙忙的就上手了一个小例子,随便爬了网站试试,算是入门级的吧,但是由于兴趣所以还是非常激动的。
前两天看了下Python基础,因为有其他语言的基础加上HTML、js都是会的,所以也就是看了下基础的语法和java有啥不同,然后一些理论知识。
我是在和自己找的一些基础视频看的,初步了解了下Python的语法,还有Python和Java的区别,对于两种语言实现相同功能的不同写法等等。
然后了解了下Python的历史,和版本的区别。
我选用的是Python3.7 。
一些基础的知识暂时没做笔记,基本是参考廖雪峰博客还有网上的一些视频网站视频就能明白的。 要深入的话最好是买下书籍来看吧。
基础还有些并没有很通透吧,想着做的时候再单个知识点去深入。
好吧,言归正传。这个示例还是非常简单得,因为之前有看过相关视频,所以还算是理解。
目标是爬取美图吧首页的一些数据。
获取页面
Python对网页访问首先需要引入urllib.request (之前直接用urllib不行好像是版本的原因,感觉我都学岔版本了)
urllib中有 urllib.request.urlopen(str) 方法用于打开网页并返回一个对象,调用这个对象的read()方法后能直接获得网页的源代码,内容与浏览器右键查看源码的内容一样。
| 1 | print(chardet.detect(htmlCode))
|
输出{'encoding': 'GB2312', 'confidence': 0.99, 'language': 'Chinese'} ,获取的爬取内容的编码方式
然后输出源代码
| 1 2 3 4 5 6 7 8 9 | import urllib.request
import chardet
page = urllib.request.urlopen('http://www.meituba.com/tag/juesemeinv.html') #打开网页
htmlCode = page.read() #获取网页源代码
print(chardet.detect(htmlCode)) #打印返回网页的编码方式
print(htmlCode.decode('utf-8')) #打印网页源代码
|
注意:直接输出print(htmlCode)的话会有编码问题,然后去原网页查看源代码的编码,但是运行htmlCode.decode("UTF-8")的时候,出现下面的错误:
line 19, in data = data.decode("UTF-8")UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte
可能是print的原因,也有肯能不是utf-8编码。可以试试,data = htmlCode.decode("UTF-8") print(data)
把爬取的网页源代码保存到文档中
| 1 2 3 4 5 6 7 8 9 10 11 12 13 | import urllib.request
import chardet
page = urllib.request.urlopen('http://www.meituba.com/tag/juesemeinv.html') #打开网页
htmlCode = page.read() #获取网页源代码
#print(chardet.detect(htmlCode)) #查看编码方式
data = htmlCode.decode('utf-8')
#print(data) #打印网页源代码
pageFile = open('pageCode.txt','wb')#以写的方式打开pageCode.txt
pageFile.write(htmlCode)#写入
pageFile.close()#开了记得关
|
这样在test.py目录下就会生成一个pageCode.txt文件了。
获取其他信息
打开pageCode.txt文件(也可以直接在原网页F12调试获取),查看需要获取数据的标签信息。
比如我现在要拿图片
写出图片的正则表达式: reg = r'src="(.+?\.jpg)"'
解释下吧——匹配以src="开头然后接一个或多个任意字符(非贪婪),以.jpg" 结尾的字符串。比如图中红框内src后 双引号里的链接就是一个匹配的字符串。
接着我们要做的就是从get_html方法返回的辣么长一串字符串中 拿到 满足正则表达式的 字符串。
用到python中的re库中的 re.findall(str) 它返回一个满足匹配的字符串组成的列表
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | import urllib.request
import chardet
import re
page = urllib.request.urlopen('http://www.meituba.com/tag/juesemeinv.html') #打开网页
htmlCode = page.read() #获取网页源代码
#print(chardet.detect(htmlCode)) #查看编码方式
data = htmlCode.decode('utf-8')
#print(data) #打印网页源代码
#pageFile = open('pageCode.txt','wb')#以写的方式打开pageCode.txt
#pageFile.write(htmlCode)#写入
#pageFile.close()#开了记得关
reg = r'src="(.+?\.jpg)"'#正则表达式
reg_img = re.compile(reg)#编译一下,运行更快
imglist = reg_img.findall(data)#进行匹配
for img in imglist:
print(img)
|
输出结果
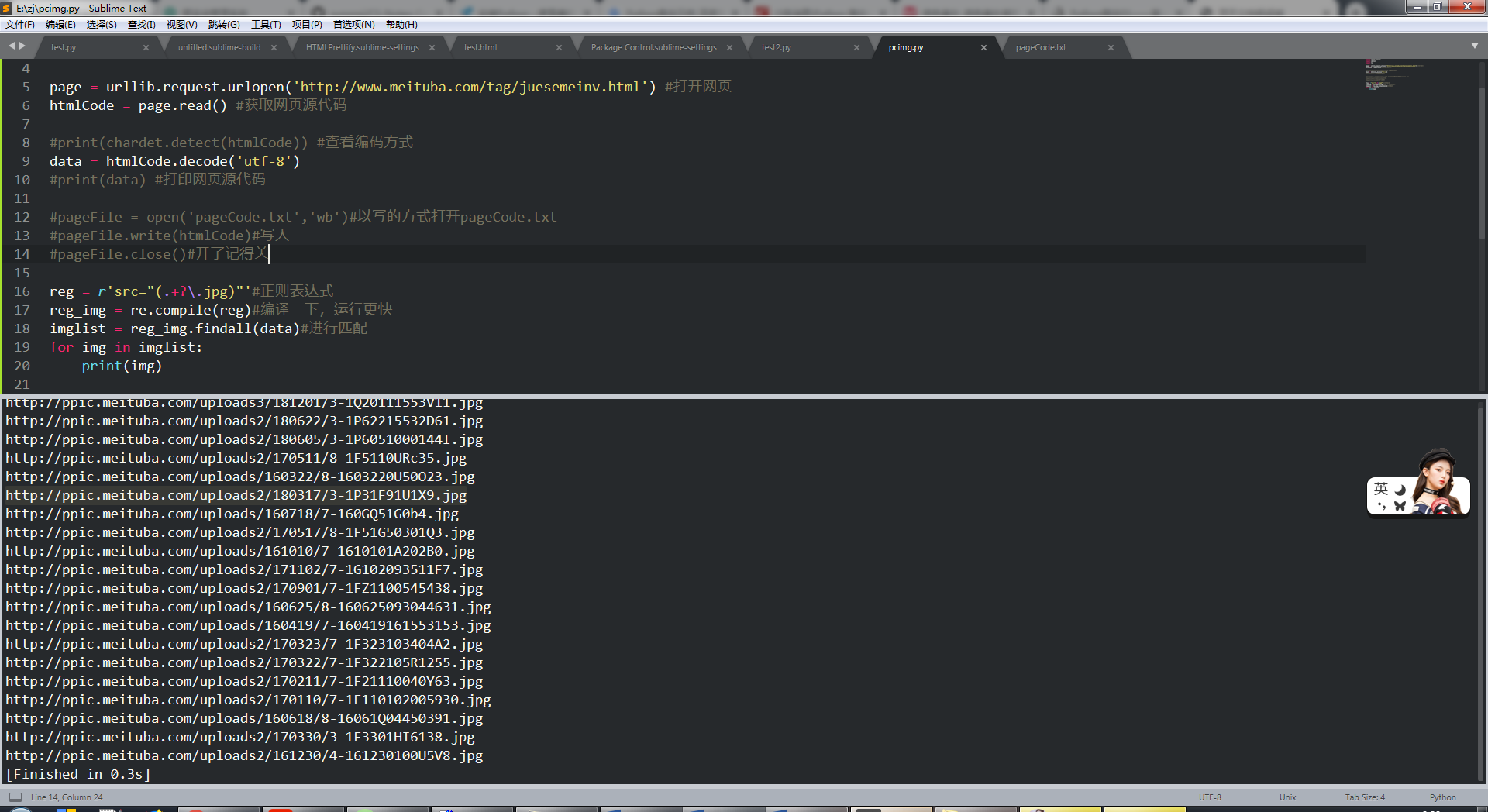
然后将图片下载到本地
urllib库中有一个 urllib.request.urlretrieve(链接,名字) 方法,它的作用是以第二个参数为名字下载链接中的内容,我们来试用一下
| 1 2 3 4 5 | x = 0
for img in imglist:
print(img)
urllib.request.urlretrieve('http://ppic.meituba.com/uploads/160322/8-1603220U50O23.jpg', '%s.jpg' % x)
x += 1
|
发现报错
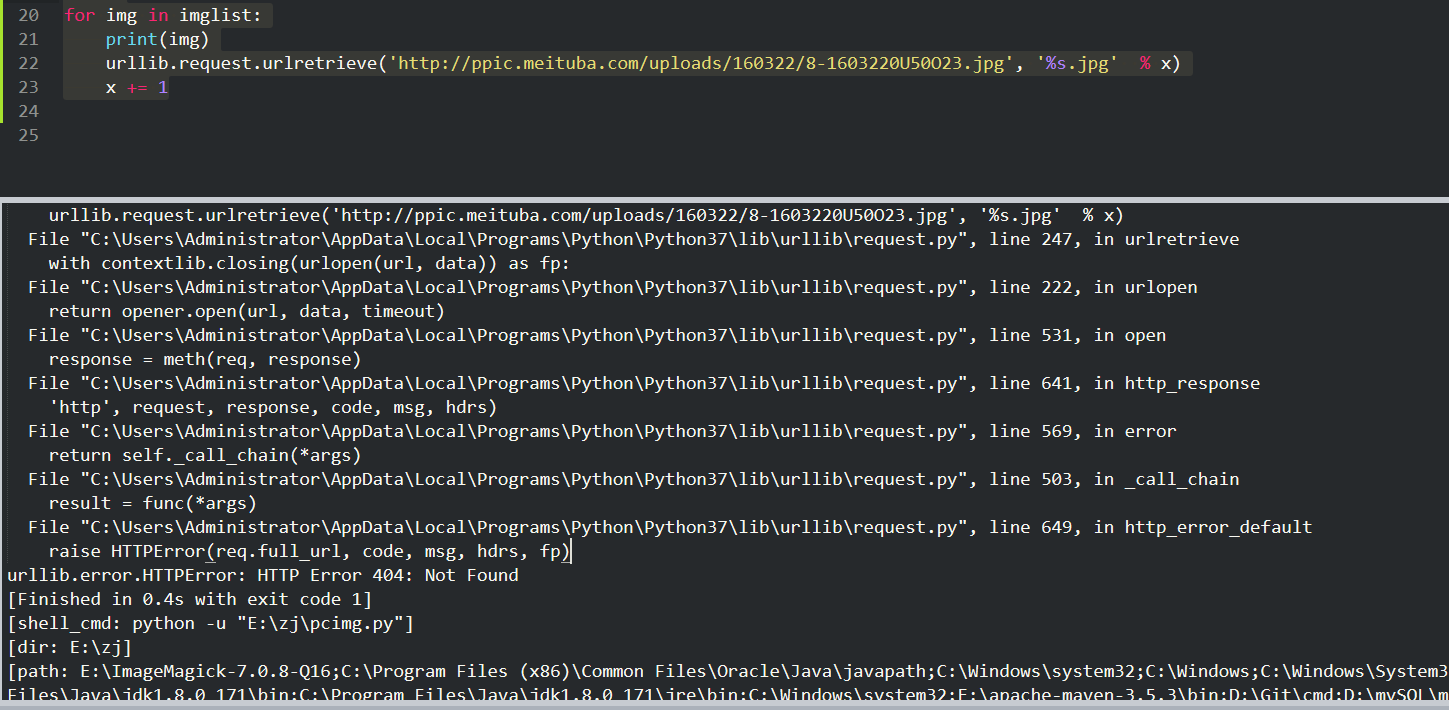
应该是被拦截了,只有通过浏览器访问的才可以下载,防爬虫的。
加上请求头应该可以的。。。
换个网站试试吧,百度图片 。。也不行啊
新浪图片。。终于OK了。。

再试一个: 爬取网络小说
首先爬取所有章节,再根据每个章节的超链接获取每章的正文内容保存到本地
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | import re
import urllib.request
def getGtmlCode():
html = urllib.request.urlopen("http://www.quanshuwang.com/book/44/44683").read() #获取网页源代码
html = html.decode("gbk") #转成该网站格式
reg = r'<li><a href="(.*?)" title=".*?">(.*?)</a></li>' #根据网站样式匹配的正则:(.*?)可以匹配所有东西,加括号为我们需要的
reg = re.compile(reg)
urls = re.findall(reg, html)
for url in urls:
#print(url)
chapter_url = url[0] #章节路径
chapter_title = url[1] #章节名
chapter_html = urllib.request.urlopen(chapter_url).read() #获取该章节的全文代码
chapter_html = chapter_html.decode("gbk")
chapter_reg = r'</script> .*?<br />(.*?)<script type="text/javascript">' #匹配文章内容
chapter_reg = re.compile(chapter_reg,re.S)
chapter_content = re.findall(chapter_reg, chapter_html)
for content in chapter_content:
content = content.replace(" ","") #使用空格代替
content = content.replace("<br />","") #使用空格代替
print(content)
f = open('{}.txt'.format(chapter_title),'w') #保存到本地
f.write(content)
getGtmlCode()
|
最后结果:
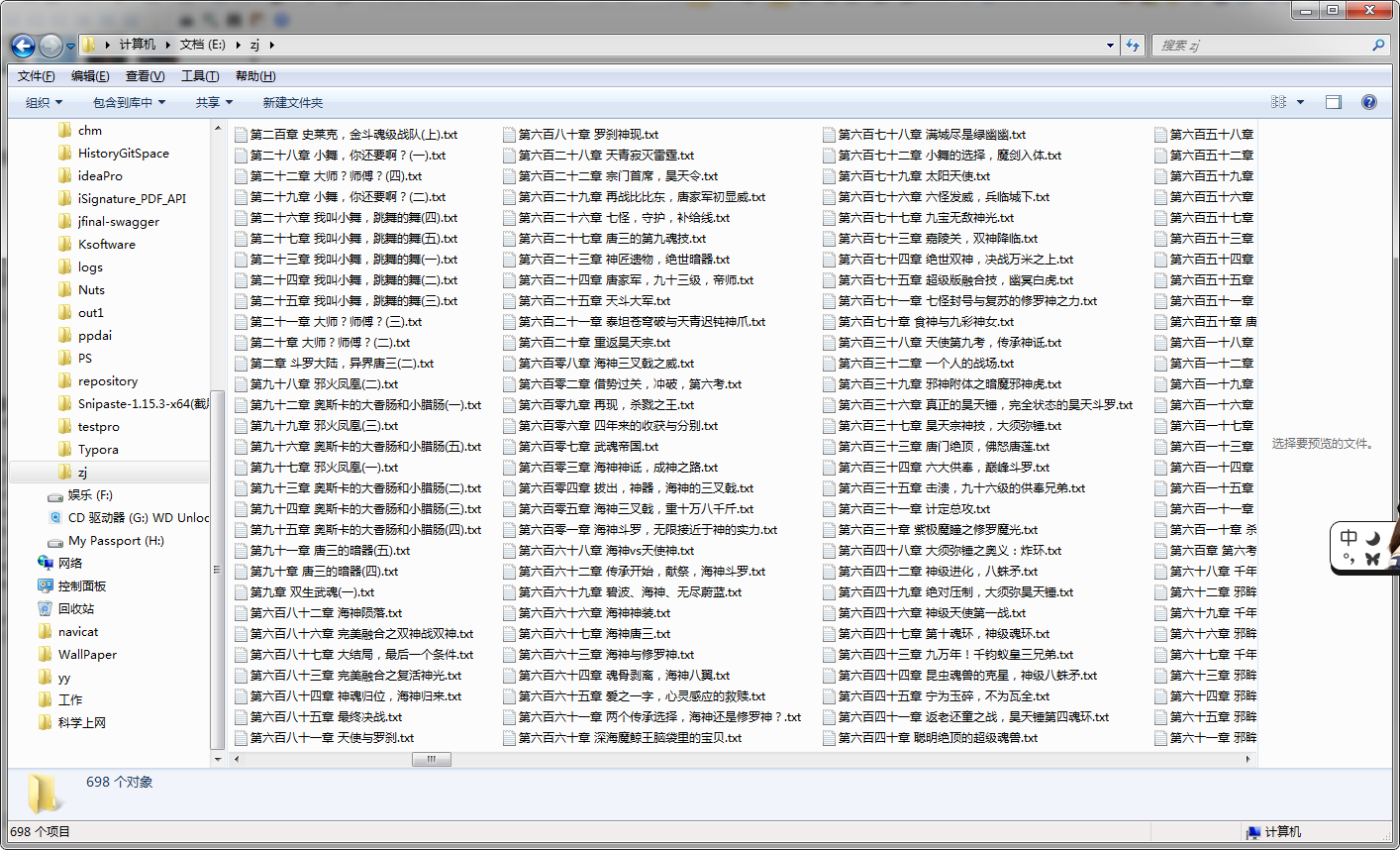
。。好多网站并没那么容易就爬的到数据啊(页面规则不统一),之前想爬微博的数据但是需要登录或者其他的验证(反爬虫机制), 还有就是把爬取的直接存到数据库再通过一定规则展现出来等等(爬下来的数据处理)。。 后面还要再学吧,知识学不完滴。
转载地址:http://vhwxi.baihongyu.com/